Memory ordering
Memory ordering describes the order of accesses to computer memory by a CPU. The term can refer either to the memory ordering generated by the compiler during compile time, or to the memory ordering generated by a CPU during runtime.
In modern microprocessors, memory ordering characterizes the CPUs ability to reorder memory operations - it is a type of out-of-order execution. Memory reordering can be used to fully utilize the bus-bandwidth of different types of memory such as caches and memory banks.
On most modern uniprocessors memory operations are not executed in the order specified by the program code. In single threaded programs all operations appear to have been executed in the order specified, with all out-of-order execution hidden to the programmer – however in multi-threaded environments (or when interfacing with other hardware via memory buses) this can lead to problems. To avoid problems memory barriers can be used in these cases.
Compile-time memory ordering
The compiler has some freedom to resort the order of operations during compile time. However this can lead to problems if the order of memory accesses is of importance.
Compile-time memory barrier implementation
These barriers prevent a compiler from reordering instructions during compile time – they do not prevent reordering by CPU during runtime.
- The GNU inline assembler statement
asm volatile("" ::: "memory");
or even
__asm__ __volatile__ ("" ::: "memory");
forbids GCC compiler to reorder read and write commands around it.[1]
- The C11/C++11 command
atomic_signal_fence(memory_order_acq_rel);
forbids the compiler to reorder read and write commands around it.[2]
- Intel ECC compiler uses "full compiler fence"
__memory_barrier()
- Microsoft Visual C++ Compiler:[5]
_ReadWriteBarrier()
Runtime memory ordering
In symmetric multiprocessing (SMP) microprocessor systems
There are several memory-consistency models for SMP systems:
- Sequential consistency (all reads and all writes are in-order)
- Relaxed consistency (some types of reordering are allowed)
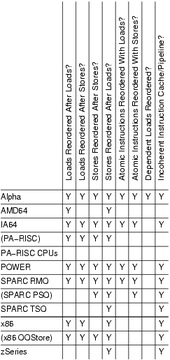
- Loads can be reordered after loads (for better working of cache coherency, better scaling)
- Loads can be reordered after stores
- Stores can be reordered after stores
- Stores can be reordered after loads
- Weak consistency (reads and writes are arbitrarily reordered, limited only by explicit memory barriers)
On some CPUs
- Atomic operations can be reordered with loads and stores.
- There can be incoherent instruction cache pipeline, which prevents self-modifying code from being executed without special instruction cache flush/reload instructions.
- Dependent loads can be reordered (this is unique for Alpha). If the processor fetches a pointer to some data after this reordering, it might not fetch the data itself but use stale data which it has already cached and not yet invalidated. Allowing this relaxation makes cache hardware simpler and faster but leads to the requirement of memory barriers for readers and writers.[6]
| Type | Alpha | ARMv7 | PA-RISC | POWER | SPARC RMO | SPARC PSO | SPARC TSO | x86 | x86 oostore | AMD64 | IA-64 | zSeries |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Loads reordered after loads | Y | Y | Y | Y | Y | Y | Y | |||||
| Loads reordered after stores | Y | Y | Y | Y | Y | Y | Y | |||||
| Stores reordered after stores | Y | Y | Y | Y | Y | Y | Y | Y | ||||
| Stores reordered after loads | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y |
| Atomic reordered with loads | Y | Y | Y | Y | Y | |||||||
| Atomic reordered with stores | Y | Y | Y | Y | Y | Y | ||||||
| Dependent loads reordered | Y | |||||||||||
| Incoherent instruction cache pipeline | Y | Y | Y | Y | Y | Y | Y | Y | Y | Y |
Some older x86 and AMD systems have weaker memory ordering[9]
SPARC memory ordering modes:
- SPARC TSO = total store order (default)
- SPARC RMO = relaxed-memory order (not supported on recent CPUs)
- SPARC PSO = partial store order (not supported on recent CPUs)
Hardware memory barrier implementation
Many architectures with SMP support have special hardware instruction for flushing reads and writes during runtime.
lfence (asm), void_mm_lfence(void) sfence (asm), void_mm_sfence(void)[10] mfence (asm), void_mm_mfence(void)[11]
sync (asm)
sync (asm)
mf (asm)
dcs (asm)
dmb (asm) dsb (asm) isb (asm)
Compiler support for hardware memory barriers
Some compilers support builtins that emit hardware memory barrier instructions:
- GCC,[13] version 4.4.0 and later,[14] has
__sync_synchronize. - Since C11 and C++11 an `atomic_thread_fence()` command was added.
- The Microsoft Visual C++ compiler[15] has
MemoryBarrier(). - Sun Studio Compiler Suite[16] has
__machine_r_barrier,__machine_w_barrierand__machine_rw_barrier.
See also
References
- ↑ GCC compiler-gcc.h
- ↑
- ↑ ECC compiler-intel.h
- ↑ Intel(R) C++ Compiler Intrinsics Reference
Creates a barrier across which the compiler will not schedule any data access instruction. The compiler may allocate local data in registers across a memory barrier, but not global data.
- ↑ Visual C++ Language Reference _ReadWriteBarrier
- ↑ Reordering on an Alpha processor by Kourosh Gharachorloo
- ↑ Memory Ordering in Modern Microprocessors by Paul McKenney
- ↑ Memory Barriers: a Hardware View for Software Hackers, Figure 5 on Page 16
- ↑ Table 1. Summary of Memory Ordering, from "Memory Ordering in Modern Microprocessors, Part I"
- ↑ SFENCE — Store Fence
- ↑ MFENCE — Memory Fence
- ↑ Data Memory Barrier, Data Synchronization Barrier, and Instruction Synchronization Barrier.
- ↑ Atomic Builtins
- ↑ http://gcc.gnu.org/bugzilla/show_bug.cgi?id=36793
- ↑ MemoryBarrier macro
- ↑ Handling Memory Ordering in Multithreaded Applications with Oracle Solaris Studio 12 Update 2: Part 2, Memory Barriers and Memory Fence
{kind=link}
Further reading
- Computer Architecture — A quantitative approach. 4th edition. J Hennessy, D Patterson, 2007. Chapter 4.6
- Sarita V. Adve, Kourosh Gharachorloo, Shared Memory Consistency Models: A Tutorial
- Intel 64 Architecture Memory Ordering White Paper
- Memory ordering in Modern Microprocessors part 1
- Memory ordering in Modern Microprocessors part 2
- IA (Intel Architecture) Memory Ordering on YouTube - Google Tech Talk