Graphics Core Next
Graphics Core Next (GCN) is the codename for both a series of microarchitectures as well as for an instruction set. GCN was developed by AMD for their GPUs as the successor to TeraScale microarchitecture/instruction set. The first product featuring GCN was launched in 2011[1]
GCN is used in 28 nm graphics chips in the HD 7700–7900, HD 8000, Rx 240–290, and Rx 300 series of AMD graphics cards. GCN is also used in the AMD Accelerated Processing Units code-named "Temash", "Kabini", "Kaveri", "Carrizo", "Beema" and "Mullins", as well as in Liverpool (PlayStation 4) and Durango (Xbox One).
GCN is a RISC SIMD (or rather SIMT) microarchitecture contrasting the VLIW SIMD architecture of TeraScale. GCN requires considerably more transistors than TeraScale, but offers advantages for GPGPU computation. It makes the compiler simpler and should also lead to better utilization . GCN implements HyperZ.[2]
Instruction set
The GCN instruction set is owned by AMD as the x86 instruction set is owned by Intel or the MIPS instruction set by Imagination Technologies. The GCN instruction set has been developed specifically for GPUs (and GPGPU) and e.g. has no micro-operation for division.
Documentation is available:
- Documentation for GCN 1.0 instruction set: http://developer.amd.com/wordpress/media/2012/12/AMD_Southern_Islands_Instruction_Set_Architecture.pdf
- Documentation for GCN 1.1 instruction set: http://developer.amd.com/wordpress/media/2013/07/AMD_Sea_Islands_Instruction_Set_Architecture.pdf
- Documentation for GCN 1.2 instruction set: http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2013/07/AMD_GCN3_Instruction_Set_Architecture.pdf
- Documentation for GCN 1.3/2.0 instruction set: to be released by AMD
An LLVM code generator (i.e. a compiler back-end) is available for the GCN instruction set.[3] It is used e.g. by Mesa 3D.
MIAOW, an open-source RTL implementation of the AMD Southern Islands GPGPU instruction set (aka GCN 1.0):
In November 2015, AMD announced an initiative named `Boltzmann`. The AMD Boltzmann initiative shall enable the porting of CUDA-based applications to a common C++ programming model.[4]
At the "Super Computing 15" AMD showed their Heterogeneous Compute Compiler (HCC), a headless Linux driver and HSA runtime infrastructure for cluster-class, High Performance Computing (HPC) and the Heterogeneous-compute Interface for Portability (HIP) tool for porting CUDA-based applications to a common C++ programming model.
Microarchitectures
As of January 2016 the family of microarchitectures implementing the identically called instruction set "Graphics Core Next" has seen three iterations. The differences in the instruction set are rather minimal, and microarchitectures also do not differentiate too much from one another.
Command processing

Graphics Command Processor
The "Graphics Command Processor" is functional unit of the GCN microarchicture. Among other tasks, it is responsible for Asynchronous Shaders. The short video AMD Asynchronous Shaders visualizes the differences between "multi thread", "preemption" and "Asynchronous Shaders".
- http://amd-dev.wpengine.netdna-cdn.com/wordpress/media/2012/10/Asynchronous-Shaders-White-Paper-FINAL.pdf
- http://www.anandtech.com/show/9124/amd-dives-deep-on-asynchronous-shading
Asynchronous Compute Engine
The Asynchronous Compute Engine (ACE) is a distinct functional block serving computing purposes. It purpose is similar to that of the Graphics Command Processor.
Scheduler
The Scheduler was mentioned together with the Polaris microarchitecture.
In 2015 Axel Davy wrote a software scheduler for the radeonsi driver stack.[5]
Geometric processor

The geometry processor contains the Geometry Assembler, the Tesselator and the Vertex Assembler.
The GCN Tesselator of the Geometry processor is capable of doing tessellation in hardware as defined by Direct3D 11 and OpenGL 4.
The GCN Tesselator is AMD's most current SIP block, earlier units were ATI TruForm and hardware tessellation in TeraScale.
Compute Units
Each Compute Unit consists of a CU Scheduler, a Branch & Message Unit, 4 SIMD Vector Units (each 16-lane wide), 4 64KiB VGPR files, 1 scalar unit, a 4 KiB GPR file, a local data share of 64 KiB, 4 Texture Filter Units, 16 Texture Fetch Load/Store Units and a 16 KiB L1 Cache. Four Compute units are wired to share an Instruction Cache 16 KiB in size and a scalar data cache 32KiB in size. These are backed by the L2 cache. A SIMD-VU operates on 16 elements at a time (per cycle), while a SU can operate on one a time (one/cycle). In addition the SU handles some other operations like branching.
Every SIMD-VU has some private memory where it stores its registers. There are two types of registers: scalar registers (s0, s1, etc.), which hold 4 bytes number each, and vector registers (v0, v1, etc.), which represent a set of 64 4 bytes numbers each. When you operate on the vector registers, every operation is done in parallel on the 64 numbers. Every time you do some work with them, you actually work with 64 inputs. For example, you work on 64 different pixels at a time (for each of them the inputs are slightly different, and thus you get slightly different color at the end).
Every SIMD-VU has room for 512 scalar registers and 256 vector registers.
What AMD calls a CU (compute unit) can be compared to what Nvidia calls an SM (streaming multiprocessor). While all CU versions consist of 64 shader processors (i.e. 4 SIMD Vector Units (each 16-lane wide)= 64), Nvidia (regularly calling shader processors "CUDA cores") experimented with very different numbers:
- one Tesla SM combines 8 single-precision (FP32) shader processors
- one Fermi SM combines 32 single-precision (FP32) shader processors
- one Kepler SM combines 192 single-precision (FP32) shader processors and also 64 double-precision units (at least the GK110 GPUs)
- one Maxwell SM combines 128 single-precision (FP32) shader processors
- one Pascal SM combines 64 single-precision (FP32) shader processors and also 32 double-precision (FP64) (at least the GP100 GPUs) providing a 2:1 ratio of single- to double-precision throughput.
CU Scheduler
The CU scheduler is the hardware functional block choosing for the SIMD-VU which wavefronts to execute. It picks one SIMD-VU per cycle for scheduling. This is not be confused with other schedulers, in hardware or software.
- Wavefront
- A 'shader' is a small program written in GLSL which performs graphics processing, and a 'kernel' is a small program written in OpenCL and going GPGPU processing. These processes don't need that many registers, they need to load data from system or graphics memory. This operation comes which significant latency. AMD and Nvidia chose similar approaches to hide this unavoidable latency: the grouping of multiple threads. AMD calls such a group a wavefront, Nvidia calls it a warp. A group of threads is the most basic unit of scheduling of GPUs implementing this approach to hide latency, is minimum size of the data processed in SIMD fashion, the smallest executable unit of code, the way to processes a single instruction over all of the threads in it at the same time.
In all GCN-GPUs, a “wavefront” consists of 64 threads, and in all Nvidia GPUs a “warp” consists of 32 threads.
AMD's solution is, to attribute multiple wavefronts to each SIMD-VU. The hardware distributes the registers to the different wavefronts, and when one wavefront is waiting on some result, which lies in memory, the CU Scheduler decides to make the SIMD-VU work on another wavefront. Wavefronts are attributed per SIMD-VU. SIMD-VUs do not exchange wavefronts. At max 10 wavefronts can be attributed per SIMD-VU (thus 40 per CU).
AMD CodeXL shows tables with the relationship between number of SGPRs and VGPRs to the number of wavefronts, but basically for SGPRS it is min(104, 512/numwavefronts) and VGPRS 256/numwavefronts.
Note that in conjunction with the SSE instructions this concept of most basic level of parallelism is often called a "vector width". The vector width is characterized by the total number of bits in it.
SIMD Vector Unit
Each SIMD Vector Unit has:
- a 16-lane integer and floating point vector Arithmetic Logic Unit (ALU)
- 64 KiB Vector General Purpose Register (VGPR) file
- A 48-bit Program Counter
- Instruction buffer for 10 wavefronts
- A wavefront is a group of 64 threads: the size of one logical VGPR
- A 64-thread wavefront issues to a 16-lane SIMD Unit over four cycles
Each SIMD-VU has 10 wavefront instruction buffer, and it takes 4 cycles to execute one wavefront.
Audio and video acceleration SIP blocks
The biggest differences lie in the additional ASIC blocks available on the concrete chips (dies). Such ASIC blocks (Unified Video Decoder, Video Coding Engine, AMD TrueAudio, etc.) have nothing to do with either the GCN microarchitecture nor with the GCN instruction set. These are simply ASIC blocks that are present on all or most chips implementing a certain iteration of GCN. As this article is actually supposed to document the GCN instruction set and microarchitecures it is a bit confusing to find information on the ASIC blocks here as well.
Unified virtual memory
In a preview in 2011, AnandTech wrote about the unified virtual memory, supported by Graphics Core Next.[6]
|




Heterogeneous System Architecture (HSA)

Some of the specific HSA-features implemented in the hardware need support from the operating system's kernel (its subsystems) and/or from specific device drivers. For example, in July 2014 AMD published a set of 83 patches to be merged into Linux kernel mainline 3.17 for supporting their Graphics Core Next-based Radeon graphics cards. The special driver titled "HSA kernel driver" resides in the directory /drivers/gpu/hsa while the DRM-graphics device drivers reside in /drivers/gpu/drm[9] and augments the already existent DRM driver for Radeon cards.[10] This very first implementation focuses on a single "Kaveri" APU or on a "Berlin" APU and works alongside the existing Radeon kernel graphics driver (kgd).
Iterations
Graphics Core Next "GCN 1.0" (Southern Islands, HD 7000/Rx 200 Series)
- Support for 64-bit addressing (x86-64 address space) with unified address space for CPU and GPU[6]
- Support for PCI-E 3.0[11]
- GPU sends interrupt requests to CPU on various events (such as page faults)
- Support for Partially Resident Textures,[12] which enable virtual memory support through DirectX and OpenGL extensions
- AMD PowerTune support, which dynamically adjusts performance to stay within a specific TDP
- Support for Mantle (API)
The GCN 1.0 (officially called "Southern Islands") microarchitecture combines 64 shader processors with 4 TMUs and 1 ROP to a compute unit (CU). There are Asynchronous Compute Engines (ACE) controlling computation and dispatching.[13][14]
ZeroCore Power
ZeroCore Power is a long idle power saving technology.[15] AMD ZeroCore Power technology supplements AMD PowerTune.
Chips
Discrete GPUs (Southern Islands family):
- Oland
- Cape Verde
- Pitcairn
- Tahiti
GCN 2nd Generation "GCN 1.1" (Sea Islands, HD 7790 and Rx 290/260 Series)

GCN 1.1 was introduced with Radeon HD 7790 and is also found in Radeon HD 8770, R7 260/260X, R9 290/290X, R9 295X2, as well as Steamroller-based Desktop Kaveri APUs and Mobile Kaveri APUs and in the Puma-based "Beema" and "Mullins" APUs. It has multiple advantages over the original GCN, including AMD TrueAudio and a revised version of AMD's Powertune technology.
GCN 1.1 introduced an entity called "Shader Engine" (SE). A Shader Engine comprises one geometry processor, up to 11 CUs (Hawaii chip), rasterizers, ROPs, and L1 cache. Not part of a Shader Engine is the Graphics Command Processor, the 8 ACEs, the L2 cache and memory controllers as well as the audio and video accelerators, the display controllers, the 2 DMA controllers and the PCIe interface.
The A10-7850K "Kaveri" contains 8 CUs (compute units) and 8 Asynchronous Compute Engines (ACEs) for independent scheduling and work item dispatching.[16]
At AMD Developer Summit (APU) in November 2013 Michael Mantor presented the Radeon R9 290X.[17]
Chips
Discrete GPUs (Sea Islands family):
- Bonaire
- Hawaii
Integrated into APUs:
- Temash
- Kabini
- Liverpool
- Durango
- Kaveri
- Godavari
- Mullins
- Beema
- Carrizo-L
GCN 3rd Generation "GCN 1.2" (Volcanic Islands, R9 285(x) and Fury/Nano)
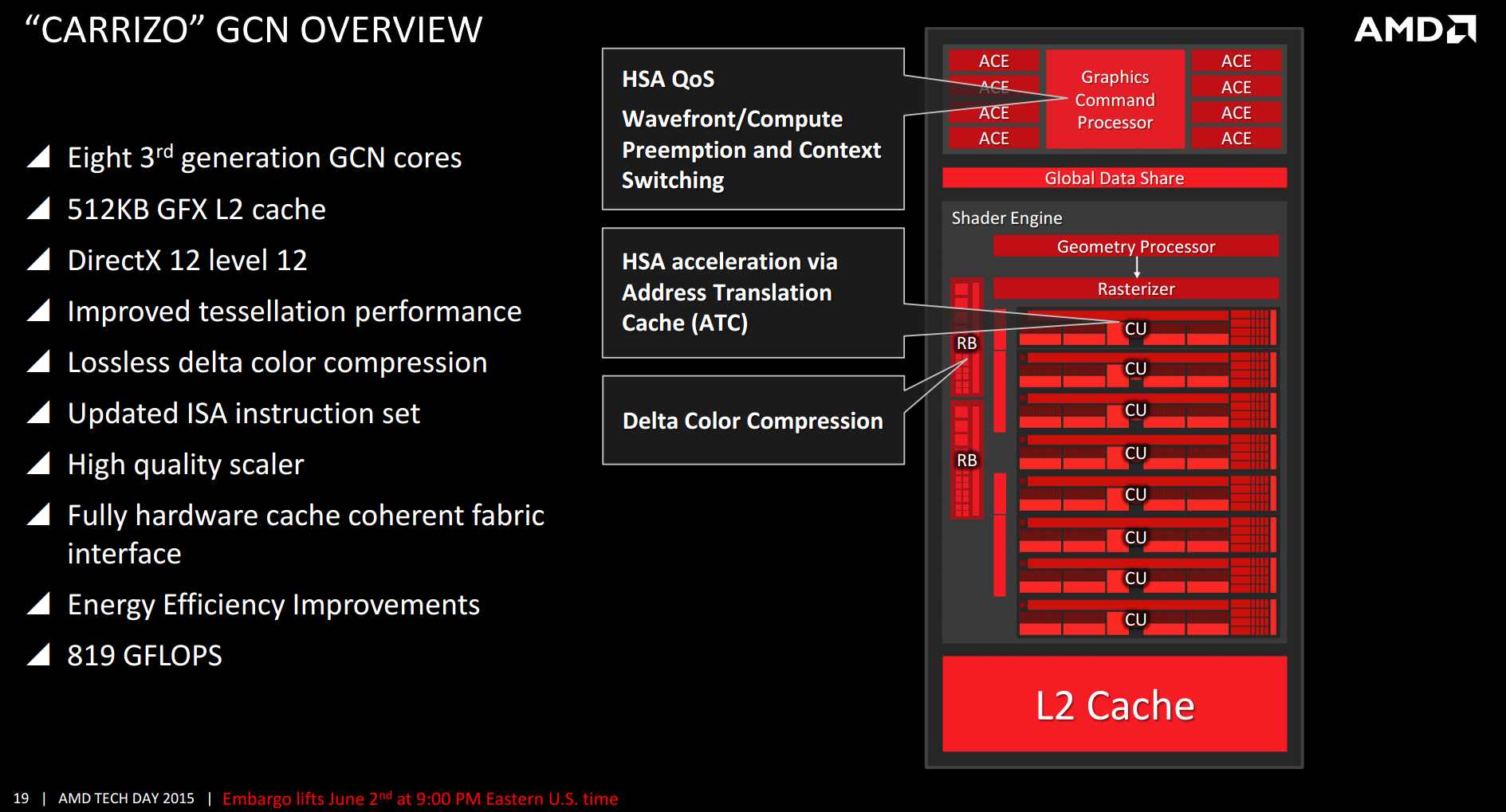
GCN 1.2 [18] was introduced with the Radeon R9 285 and R9 M295X, which have the "Tonga" GPU. It features improved tessellation performance, lossless delta color compression in order to reduce memory bandwidth usage, an updated and more efficient instruction set, a new high quality scaler for video, and a new multimedia engine (video encoder/decoder). Delta color compression is supported in Mesa.[19]
Chips
Discrete GPUs:
- Tonga (Volcanic Islands family), comes with UVD 5.0
- Fiji (Pirate Islands family), comes with UVD 6.0 and High Bandwidth Memory (HBM 1)
Integrated into APUs:
- Carrizo, comes with UVD 6.0
GCN 4th Generation "GCN 1.3" (Arctic Islands/Polaris)
GPUs of the Arctic Islands-family will be introduced in Q2 of 2016 with AMD Radeon Rx 400 Series branded graphics cards, based upon the Polaris architecture. All Polaris-based chips will be produced on the 14 nm FinFET process.[20]
Chips
Discrete GPUs:[21]
- Polaris 11
- Renamed from Baffin
- 6 dGPUs planned for release
- Polaris 10
- Renamed from Ellesmere
- 2 dGPUs planned for release
Integrated into APUs:
- Future Zen Powered APUs (launching in H1 2017)
See also
References
- ↑ "AMD Launches World’s Fastest Single-GPU Graphics Card – the AMD Radeon HD 7970" (Press release). AMD. 2011-12-22. Retrieved 2015-01-20.
- ↑ "Feature matrix of the free and open-source "Radeon" graphics device driver". Retrieved 2014-07-09.
- ↑ "LLVM back-end amdgpu".
- ↑ "AMD Boltzmann Initiative – Heterogeneous-compute Interface for Portability (HIP)". 2015-11-16. Retrieved 2016-01-15.
- ↑ "Performance comparisons with software scheduler".
- 1 2 "t the unified address space that will be used is the x86-64 address space". AnandTech. 2011-12-21. Retrieved 2014-07-11.
- ↑ "Kaveri microarchitecture". SemiAccurate. 2014-01-15.
- ↑ Dave Airlie (2014-11-26). "Merge AMDKFD". freedesktop.org. Retrieved 2015-01-21.
- ↑ "/drivers/gpu/drm". kernel.org.
- ↑ "[PATCH 00/83] AMD HSA kernel driver". LKML. 2014-07-10. Retrieved 2014-07-11.
- ↑ "AMD Radeon HD 7000 Series to be PCI-Express 3.0 Compliant". TechPowerUp. Retrieved July 21, 2011.
- ↑ "AMD Details Next Gen. GPU Architecture". Retrieved August 3, 2011.
- ↑ Mantor, Michael; Houston, Mike (2011-06-15). "AMD Graphics Core Next" (pdf). AMD. p. 40. Retrieved 2014-07-15.
Asynchronous Compute Engine (ACE)
- ↑ "AMD's Graphics Core Next Preview: AMD's New GPU, Architected For Compute". AnandTech. 2011-12-21. Retrieved 2014-07-15.
AMD's new Asynchronous Compute Engines serve as the command processors for compute operations on GCN. The principal purpose of ACEs will be to accept work and to dispatch it off to the CUs for processing.
- ↑ "Managing Idle Power: Introducing ZeroCore Power". AnandTech. 2011-12-22. Retrieved 2015-04-29.
- ↑ "AMD's Kaveri A10-7850K tested". AnandTech. 2014-01-14. Retrieved 2014-07-07.
- ↑ "AMD Radeon R9-290X". 2013-11-21.
- ↑ http://images.anandtech.com/doci/9319/Slide%2019%20-%20GCN%20Overview.png
- ↑ "Add DCC Support". 2015-10-11.
- ↑ http://www.guru3d.com/articles-pages/radeon-technologies-group-january-2016-amd-polaris-architecture,1.html
- ↑ "AAMD confirms Polaris 10 is Ellesmere and Polaris 11 is Baffin". VideoCardzx. 24 March 2016. Retrieved 8 April 2016.
|first1=missing|last1=in Authors list (help)
{kind=link}
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||